


※本記事は、2018年7月11日にAras Corporation MARK REISIGによって投稿された記事を和訳したものです。
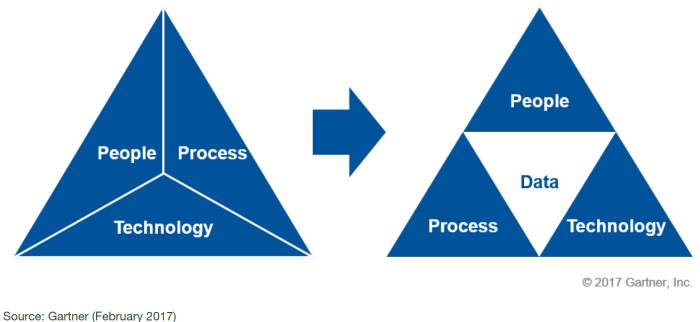
耳の痛い話ですが、PLMシステムやその他のシステムの価値は、結局は使用するデータ次第であるということです。つまりガーベッジ・イン・ガーベッジ・アウト(GIGO)、無意味なデータを入力しても無意味な結果しか得られないのです。不十分なPLMシステムが、サプライチェーン上のデータ品質問題を拡大させる可能性も時にはあります。多くの方は、GartnerのPeople、Processes、Technologyの三角形図をご覧になっていると思いますが、データもこの3つの一部分として同様に重要です。GartnerのMaster Data Management(MDM)アナリストは、データは根本的な基盤であるとしています。
隠されたデータ・ファクトリ
次のハーバード・ビジネス・レビューの記事「無意味なデータにかけている費用、年間3兆米ドル」では、IBMは、2016年において年間3兆ドルもの問題になったと主張しています。
この記事で述べられているように、この問題は、「隠されたデータ・ファクトリ」と呼ばれます。出荷された製品、再加工されたBOM、間違ったデータ、欠落したデータ、手書きの引き継ぎ書などを収集することに労力を費やしていることは、バリューチェーン全体に、そして直接的に会社の利益率にも影響を与えます。
たとえば、厳密な新規作成プロセスがない場合、同じフォーム、フィット、ファンクション(FFF)を持つ部品に重複した部品番号をふることもできてしまいます。これにより、多くの品質原価(COQ)問題が起き、サプライチェーンで数百万ドルが無駄になります。さらに、貧弱なデータ戦略と、本来はデジタルスレッドを通じて品質データにアクセスできるものであるはずの製品イノベーションプラットフォームとしての機能を果たさないPLMシステムのために、製品データを手動で修正していると、年間では何千時間もの無駄が発生します。
「部品」と「原材料」という2つのアイテムMDMオブジェクトは、製造業の収益の約50%を占めます。一方で、データの品質が重視されることはほとんどなく、コスト削減の分野としては無視されることが度々あります。無視される理由を2つ考察します。まず、部品は通常、異なる縦割りの部門(データサイロ)間を動くものであるからです。これにより、ある部門が他の部門に情報を共有しないため、無意味なデータによる意図しない結果が起こることにもう一方の部門が気が付かなかったり、データの欠如に気づかなかったりといった問題が生じます。第二に、部門間で情報が変わっていくため、そのような小さなものを追いかけるのに私たちはうんざりしているのです。幸運にもそれを理解できる知識を持つ人がいたとしても、それは役員・幹部レベルの人ではありません。これが、データサイエンティスト、ビッグデータ、機械学習、AIを雇う理由ではありませんか?
業界データの科学者の最近の調査によれば、79%の時間がデータの収集、整理、精査に費やされ、無駄になっています。データサイエンティスト、ビッグデータ、機械学習、AIはすべて、データを最大限に活用するためのものですが、アイテムMDMのベストプラクティスに従えないのであれば、競合他社よりもデータを溜め込むデータ戦略で、受け身でデータを操る練習をしているに過ぎません。
データはデジタル時代における石油
優れたデータ品質は、コネクティビティとイノベーションの燃料となります。エコノミストはデータを「デジタル時代の石油」と呼んでいます。私たちはいま、サービスとしての能力を提供するというビジネスの根本的な変化を目の当たりにしています。将来に備える企業は、競争優位性を得るためにデータを活用する必要があります。それができないと、そういった企業に負けてしまうことになるでしょう。
現在、企業は、古くからの縦割りサイロを跨ぎライフサイクルを通じて製品データが繋がるデータフローを実現するプラットフォーム、デジタルスレッドを必要としています。デジタルスレッドは「適切なタイミングで適切なデータを」提供することの水準を上げました。これからはデータを最大限に活用する、顧客主導の企業の時代がやってきます。アマゾン、アップル、マイクロソフトなど多くの企業は、驚くほどデータを活用、再利用して、ビジネスのやり方を変えています。
プロセスとテクノロジーは成功に不可欠ですが、使用するデータも同じくらい重要です。強力なデータと流動的なデジタルスレッドを有する企業は、統計、機械学習、AIを活用してより効率的であるだけでなく、社員をよりクリエイティブな仕事に向かわせます。優れたデータはすべてを良くし、悪いデータは悪くします。優れたデータは、あらゆる企業の成功にとって基盤となり、社員やプロセス、技術、データ標準や自社製品よりも長持ちします。その結果、どのテクノロジーもオープンで、複数のデータモデルを処理できることが重要です。
テクノロジーには、極めて高い拡張性が求められます。データの量が爆発的に増加しているからです。IDCは、2020年には世界的な支出が1兆2,000億ドルに達し(15.5%の年平均成長率)、2025年には「デジタルユニバース」(毎年作られ、コピーされるデータ)が180ゼタバイト(21桁)に達すると予測しています。ライフサイクル全体を通じて製品データを管理する必要が生じ、そのためには、デジタルスレッドを流れる製品データをコントロールする必要があります。
アイテムMDMデータ
顧客、サプライヤー、見込み顧客、市民、企業の各拠点、または勘定コード表にとって、「材料」または「製品」データとも呼ばれるアイテムMDMデータは、製品(部品、材料、ツールなど)を製造する企業全体で使用される重要なビジネスデータです。アイテムMDMオブジェクトである「部品」は、ビジネスに不可欠な部品番号、名前、詳細説明、測定単位などの属性を追跡します。すべてのMDMオブジェクトには、SOT(Source of Truth=信頼できる情報源)があり、SOR(System of Record=記録のためのシステム)と呼ばれる、データが追加・更新される多種のシステムで管理されています。SOTと、複数の繋がったSORが一緒になってデジタルスレッドを構成します。
「新しいパーツ作成」プロセスを使って、PLMのFFFに重複しない新しいパーツを作成するとしましょう。これはSORです。ArasはIHSとのパートナーシップによって、クラウド内の4000の異なるメーカーの4億3000万のコンポーネントデータを提供するIHS CAPSデータベースに部品検索を拡張し、重複率の高い部品を数百万個有する企業にコンポーネントエンジニアリングモジュールを提供しています。Arasは、既存の設計において自社製造の部品と推奨製造元から提供される部品のどちらが(もしくは両方が)使われているかを識別し、部品の再利用を容易にします。詳細はこちらでご覧いただけます。CIMdata論評:Arasコンポーネントエンジニアリング(日本語)
部品はPLM、ERP、SCMといった様々なSOR間を移動し、異なる部門のデータ所有者によって属性情報が追加・操作されます。PLMはERPに10〜30の属性を送信し、ERPでは150以上の属性が追加され、それが続いていきます。操作するうえで重要なのは、各エリアのアイテムMDM属性のデータ所有者です。そのため、ERPのプランナーは、設計が所有する部品番号属性を変更することはできず、実際のコストを見ることのできるPLMのエンジニアも、コストはERPのファイナンスが所有しているため変更できません。これがうまくいくと、このプロセスを監督する機能プロセスオーナーとガバナンスが存在します。
PLMとERPの戦略に全力を尽くしたので、良い状態であると考えているかもしれません。しかし、これはデジタルスレッド全体に関係する問題であり、途切れないデジタルスレッドを構築できている企業はほんの少ししかないため、私自身はまだ喜べないと思っています。
SOT、デジタルスレッド(多くのSORを通る旅)や、現場に出ている製品の正確な構成を制御できるのであれば、デジタルツイン(物理的な製品の仮想の描写)を使用してストリーミング中のIOTデータを活用できるだけでなく、製品の仕組みや顧客のための改善の可能性をすべて理解し、競争力を発揮することができます。
優れたアイテムMDMデータの品質を向上させることが、どんな部門で行われる作業でも取って代われるわけではありませんが、手戻りの削減、コストパフォーマンスの向上、リコールの削減、データによる意思決定、ロストの軽減、精度なコスト見通し、顧客体験の向上、迅速な革新に関する知識といった恩恵をもたらし、よりよく働けることに繋がります。
「言うは易く行うは難し」ですが、デジタルトランスフォーメーションの旅を続けながら、データをオープンで柔軟な製品イノベーションプラットフォームの重要なポイントとすることを強くお勧めします。